How to Optimize Token Spend for Better Agentic ROI
Per-unit intelligence is getting cheaper, yet agentic bills are rising. Where does the spend go and how to optimize for max ROI?
 Mike Boyarski
Mike Boyarski
We’ve entered a phase in AI where token usage continues to explode while P&L functions look closer for verified business impact. Reporting from Goldman Sachs, MIT, and others in 2025 and earlier highlighted the token value divide. Many felt the conclusion and analysis was too soon and shortsighted, after all, we still learning the promise of LLMs. Half way thru 2026 and per-unit intelligence costs are dropping roughly 10x a year while total AI costs explode. As models advance, context windows extend, and adoption accelerates, now is the right time to ask, has enough been done to optimize AI spend without sacrificing innovation?
The token usage problem isn’t about the models per se. Most organizations are running AI across a variety of use cases, learning what works, and finding repeatable patterns. The next AI adoption phase is to apply optimization learnings to maximize ROI so that more use cases can be addressed without unexpected cost overrides.
What’s Driving the Spend
Five forces are compounding and while many teams are aware of a few, most don’t have an owner or strategy to address all five.
Reasoning models burn invisible tokens. Models extended reasoning can consume 20,000–50,000 tokens before producing a 500-token answer. The thinking is hidden from the user and often forgotten as they focus on getting to a conclusion.
Agent loops compound consumption. Agent systems often re-pass full context on every iteration. A 10-step agent run with a 30,000-token prompt can quickly reach 500,000 to 2 million tokens without oversight.
The hidden bill of input volume. RAG pipelines, tool schemas, and few-shot examples can drive surprisingly large 50,000–200,000 input tokens per call. Input pricing can look cheap in isolation, until you multiply by execution frequency across a continuously running production workload.
Model upgrade creep. Teams default to Opus, GPT-4o, or Gemini Pro for tasks that Haiku or 4o-mini can handle at one-fifteenth the cost. The frontier model becomes the easy default when its overkill for the task.

An estimated 60–80% of enterprise token spend goes to use cases that haven’t proven business value. AI in the enterprise is early, much of the experimentation offers learning benefits over tangible business ROI. However, a common design and cost pattern is starting to emerge that can be applied to how agent systems are built at-scale.
The Mitigation Solution
Optimizations can be grouped into two layers. Orchestration-layer controls that determine the shape of every downstream API call and platform and infrastructure controls that are additive on top.
Orchestration-Layer Controls
This is the layer where spend controls can be made. Every choice can cascade through each API call your system makes.
Agent loop budgets and step limits. Set hard caps on iterations, token-per-task budgets, and max-cost circuit breakers prevent runaway spend. In CrewAI, max_iter, max_execution_time, and max_rpm on agents — plus max_tokens on tasks give you direct control. This prevents the $40 “summarize this doc” surprise.
Per-task model routing. Route each agent step by complexity and token profile instead of sending every step to one default model. You can use small models or code(no model at all) for deterministic classification and extraction, mid-tier models for synthesis, and reserve frontier or reasoning models for orchestration, planning, and the hardest judgement calls. CrewAI can route simple steps to Haiku 4.5, synthesis to GPT-4.1 Nano, and orchestration to Opus 4.8.
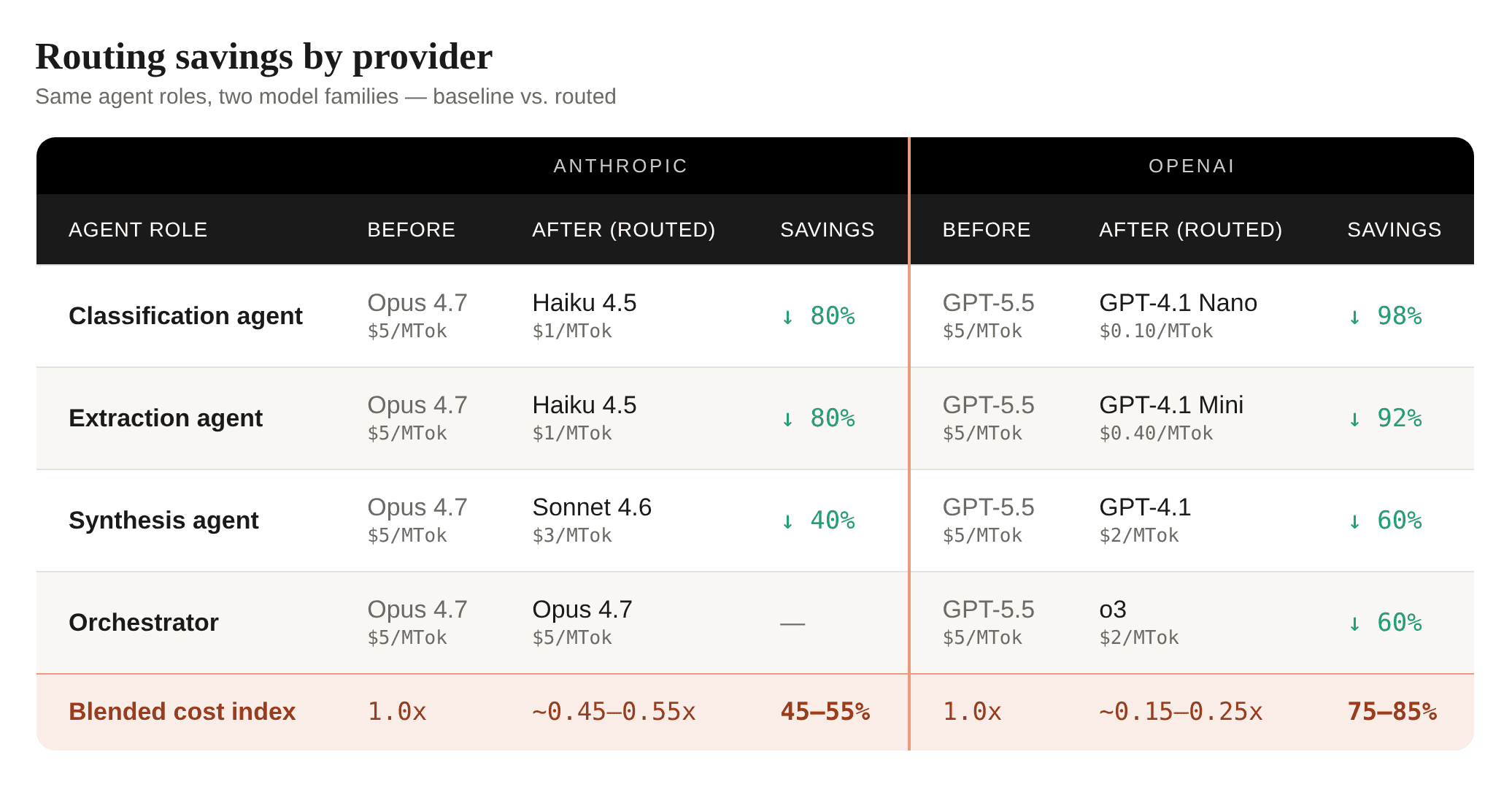
All prices are input tokens, per million, standard API rates as of June 2026. Output rates are 4–8× higher depending on provider and model. Blended index assumes equal token volume across agent roles. Actual savings depend on your workload's input/output ratio and token distribution per role. Prices verified against anthropic.com/pricing and openai.com/api/pricing.
Role and tool scoping. Control which agent has which tool. Tool schemas can inflate input tokens linearly, ten tools with 500-token schemas each adds 5,000 tokens to every single call. In CrewAI, scope tools to specific agents and use task-level context isolation so each agent only sees the information it needs.
Hierarchical vs. sequential process selection. Hierarchical orchestration (manager delegates to workers) avoids passing full conversation history between every agent. Sequential with explicit context parameters lets you forward only relevant prior outputs, not full transcripts. The architecture decision alone can cut context volume by 60%+.
Deterministic steps outside the LLM. Avoiding token use at all can be the best choice for certain workflows. Parsing, validation, lookups, and math don’t require a language model. In CrewAI, custom tools can wrap deterministic logic so the LLM orchestrates decisions rather than perform the computation.
Output structure enforcement. Output tokens cost 3–5x input tokens. Pydantic output schemas into CrewAI’s output_pydantic enforce concise, structured responses, and eliminate the verbose preambles that frontier models produce.
Platform & Infrastructure Controls
These are agent control plane levers, orthogonal to orchestration, but equally assist in driving down unnecessary usage.
Prompt caching. Anthropic offers discounts on cache hits with up to a 1-hour TTL. OpenAI provides automatic caching at roughly 50% savings. Gemini has context caching. The important requirement is stable prompt prefixes. Restructure your prompts so system instructions and tool schemas sit at the front.
Batch APIs. OpenAI, Anthropic, and Gemini all offer discounts for non-realtime workloads. Use for evaluations, backfills, and bulk content generation, use batch for anything that doesn’t need a low latency response.
Semantic caching at the app layer. Tools like GPTCache and Redis Vector catch repeat or near-duplicate queries. Teams see 30–50% hit rates on consumer-facing applications.
Self-hosting open-weight models. Llama 3.3, Qwen 2.5, and DeepSeek-V3 via Together, Fireworks, or Groq become rational choices for sustained stable workloads.
Observability. Galileo, Arize, Datadog LLM Observability. You cannot manage what you cannot measure, observability is a prerequisite to addressing the list list above.
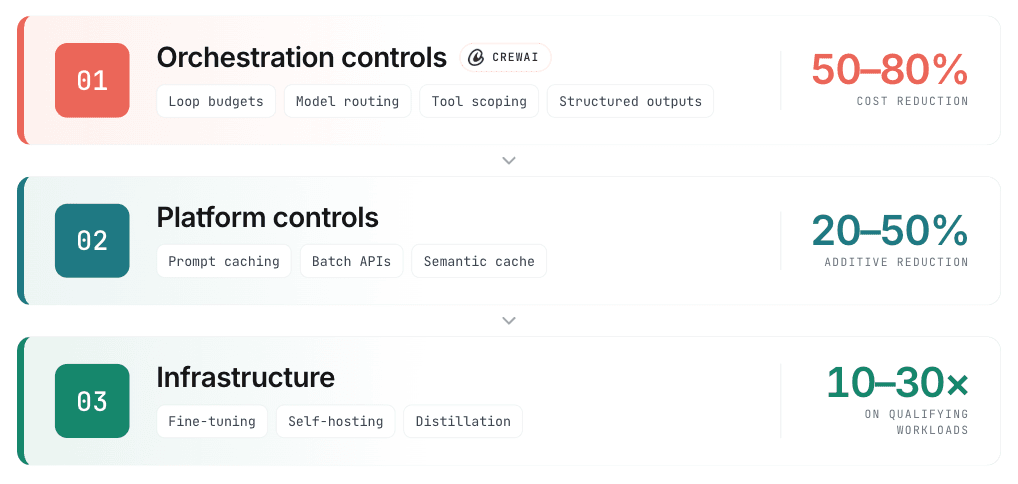
Sequencing the Optimization Journey
Teams can often address token optimization in the wrong order and get marginal gains. Here’s a suggested sequence to maximize gains quickly:

Balancing Tokens with Outcomes
We aren’t in a model pricing problem phase per se. Per-intelligence cost is falling, the AI bill is rising because organizations are scaling, exploring, and learning. The time is now to instrument your agent framework and harness to maximize token use without sacrificing innovation.
Token optimization is operational discipline at the agent build and control layer, ensuring the right automation is built while instrumenting controls to get the most out of your AI stack. The right architecture can yield 70–85% cost reductions without quality loss.
Ready to see the orchestration controls in practice? Explore CrewAI’s docs on agent iteration limits, per-agent model assignment, and hierarchical process orchestration, try the product yourself, and connect with us to discuss how to improve your agent ROI.


